This project demonstrates how to build a Convolutional Neural Network (CNN) model to enhance low-light images. Using a combination of CNN layers, we aim to transform dark and noisy images into more vibrant and clear ones. The project uses the LOL dataset, which consists of paired low-light and bright images, and includes techniques for adding noise to images for training a robust enhancement model.
Table of Content
Prerequisites
Installation Steps
Model Overview
Model Summary
Training
Inference
Example Usage
Results
References
1. Prerequisites
Google Colab (Recommended for using the mounted Google Drive and GPU support)
Keras
OpenCV
NumPy
Matplotlib
TQDM (for progress tracking)
2. Installation Steps
Clone the repository or download the code files.
Upload the LOL dataset(https://drive.google.com/drive/folders/1UBsbY3CczeT03BOF3a7-FJoHHL4aCHWf?usp=sharing) to your Google Drive.
Mount Google Drive in your Colab session:
from google.colab import drive
drive.mount('/content/drive')
4. Install necessary packages:
import numpy as np
import pandas as pd
import os
import cv2 as cv
import matplotlib.pyplot as plt
from keras import backend as K
from keras.layers import add, Conv2D,MaxPooling2D,UpSampling2D,Input,BatchNormalization, RepeatVector, Reshape
from keras.models import Model
np.random.seed(1)
5. Dataset: The dataset used is the LOL dataset for low-light image enhancement. The dataset consists of paired low-light (low) and normal light (high) images. You can download the dataset from the following link:
https://drive.google.com/drive/folders/1UBsbY3CczeT03BOF3a7-FJoHHL4aCHWf?usp=sharing
6. LOL Dataset: Place the dataset in your Google Drive and modify the InputPath to point to the correct dataset directory.
InputPath = "/content/drive/MyDrive/ml_projects/low_light_image_enhancer/LOLdataset/train/high"
3. Model Overview
This project uses a CNN model with several convolutional layers to process and enhance the input low-light images. Below are the main components of the model:
- Noise Addition: Salt-and-pepper noise is artificially added to the input images to simulate real-world noise scenarios.
def addNoise(image):
# salt and pepper noise
noiseAddedImage = np.copy(image)
# Adding salt (white) noise
num_salt = np.ceil(image.size * 0.01) # Percentage of image to be "salt"
coords = [np.random.randint(0, i, int(num_salt)) for i in image.shape[:2]]
noiseAddedImage[coords[0], coords[1], :] = 1 # Apply to all channels
# Adding pepper (black) noise
num_pepper = np.ceil(image.size * 0.01) # Percentage of image to be "pepper"
coords = [np.random.randint(0, i, int(num_pepper)) for i in image.shape[:2]]
noiseAddedImage[coords[0], coords[1], :] = 0 # Apply to all channels
return noiseAddedImage
2. Data Preprocessing: The images are resized to 500x500 pixels and converted from BGR to RGB format. The images are darkened by manipulating the HSV channels to simulate low-light conditions.
def PreProcessData(ImagePath):
X_ = []
y_ = []
count = 0
# Iterate over all images in the provided directory
for imageName in tqdm(os.listdir(HighPath)):
count += 1
imagePath = os.path.join(HighPath, imageName)
# Load the image
low_img = cv.imread(imagePath)
if low_img is None:
print(f"Warning: Skipping {imageName}, could not load the image.")
continue
# Convert BGR to RGB
low_img = cv.cvtColor(low_img, cv.COLOR_BGR2RGB)
# Resize the image to 500x500
low_img = cv.resize(low_img, (500, 500))
# Convert to HSV and darken the image by reducing the value channel
hsv = cv.cvtColor(low_img, cv.COLOR_RGB2HSV)
hsv[..., 2] = hsv[..., 2] * 0.2
img_1 = cv.cvtColor(hsv, cv.COLOR_HSV2RGB)
# Apply noise to the darkened image
Noisey_img = addNoise(img_1)
# Append the processed noisy image and original low image to the lists
X_.append(Noisey_img)
y_.append(low_img)
# Convert the lists to NumPy arrays
X_ = np.array(X_)
y_ = np.array(y_)
return X_, y_
3. CNN Architecture: A custom CNN architecture is designed, consisting of multiple layers of Conv2D with varying filter sizes, combined with add layers to combine different feature maps.
def InstantiateModel(in_):
model_1 = Conv2D(16,(3,3), activation='relu',padding='same',strides=1)(in_)
model_1 = Conv2D(32,(3,3), activation='relu',padding='same',strides=1)(model_1)
model_1 = Conv2D(64,(2,2), activation='relu',padding='same',strides=1)(model_1)
model_2 = Conv2D(32,(3,3), activation='relu',padding='same',strides=1)(in_)
model_2 = Conv2D(64,(2,2), activation='relu',padding='same',strides=1)(model_2)
model_2_0 = Conv2D(64,(2,2), activation='relu',padding='same',strides=1)(model_2)
model_add = add([model_1,model_2,model_2_0])
model_3 = Conv2D(64,(3,3), activation='relu',padding='same',strides=1)(model_add)
model_3 = Conv2D(32,(3,3), activation='relu',padding='same',strides=1)(model_3)
model_3 = Conv2D(16,(2,2), activation='relu',padding='same',strides=1)(model_3)
model_3_1 = Conv2D(32,(3,3), activation='relu',padding='same',strides=1)(model_add)
model_3_1 = Conv2D(16,(2,2), activation='relu',padding='same',strides=1)(model_3_1)
model_3_2 = Conv2D(16,(2,2), activation='relu',padding='same',strides=1)(model_add)
model_add_2 = add([model_3_1,model_3_2,model_3])
model_4 = Conv2D(16,(3,3), activation='relu',padding='same',strides=1)(model_add_2)
model_4_1 = Conv2D(16,(3,3), activation='relu',padding='same',strides=1)(model_add)
model_add_3 = add([model_4_1,model_add_2,model_4])
model_5 = Conv2D(16,(3,3), activation='relu',padding='same',strides=1)(model_add_3)
model_5 = Conv2D(16,(2,2), activation='relu',padding='same',strides=1)(model_add_3)
model_5 = Conv2D(3,(3,3), activation='relu',padding='same',strides=1)(model_5)
return model_5
4. Model Summary
* Input: 500x500 RGB image.
* Output: Enhanced 500x500 RGB image.
* Optimizer: Adam
* Loss: Mean Squared Error (MSE)
5. Training
The model is trained using noisy, darkened images as input and the corresponding high-light images as ground truth. The model is compiled using the Adam optimizer and trained over multiple epochs.
Model_Enhancer.fit(GenerateInputs(X_, y_), epochs=53, verbose=1, steps_per_epoch=8, shuffle=True)
6. Inference
Once the model is trained, you can perform inference on new low-light images. The function ExtractTestInput is used to preprocess test images, and the trained model generates enhanced images.
Prediction = Model_Enhancer.predict(image_for_test)
7. Example Usage
1.Load a test image.
2.Apply noise and darkening to simulate a low-light condition.
3.Run the model to get the enhanced image.
4.Compare the low-light image, the original image, and the enhanced output.
image_for_test = ExtractTestInput("/path/to/test/image.png")
Prediction = Model_Enhancer.predict(image_for_test)
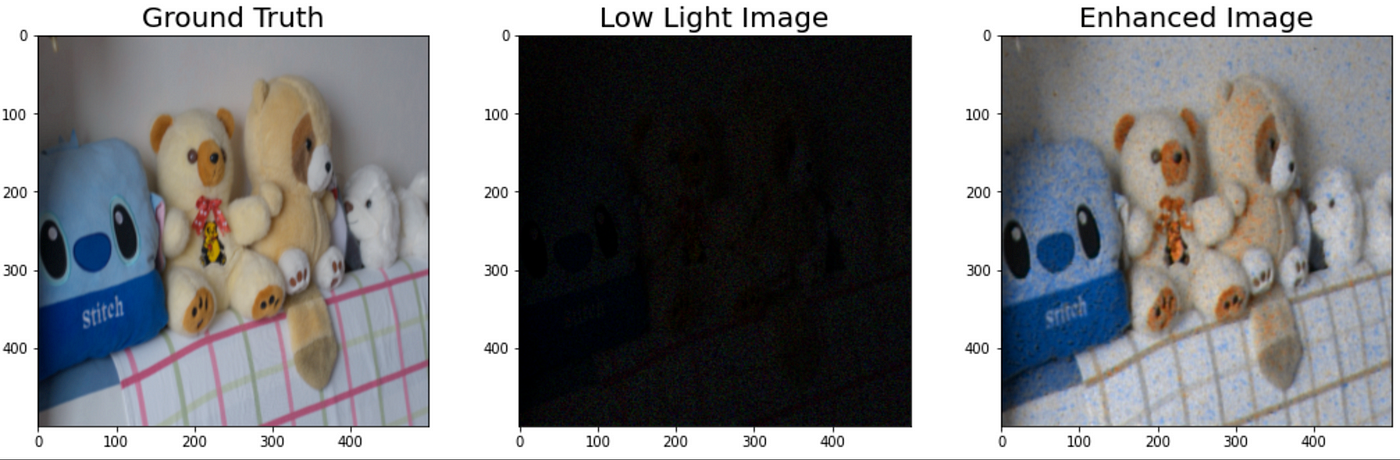
8. Results
Below are sample outputs from the model:
Original Image: The ground truth image in normal lighting.
Low Light Image: The darkened and noisy input to the model.
Enhanced Image: The output of the model, which restores brightness and reduces noise.